A seasoned professional with 5.5 years of experience in software engineering,with major area of expertise in quality assurance automation, python programming and machine learning. I have designed and developed several automation
testing solutions which have proven bug free deliverable resulting in a smooth production deployment. I aspire to develop AI solutions in the area of software quality assurance and remove as much manual intervention as possible
As part of this certification I have developed multiple machine learning projects in computer vision, speech recognition, Alexa chatbot development, and many more projects which helped me in understanding the complete lifecycle of a machine learning solution.
With this certification I got to know about the mathematical aspects of a ML model , able to develop loss functions, train complex linear regression objective functions using Octave programming language
This was a introductory certification I did at the very begining, this helped me in getting an understanding about the basic machine learning concepts , able to fine tune a pretrained model to recognise the type of flower from an input image.
Contact Me
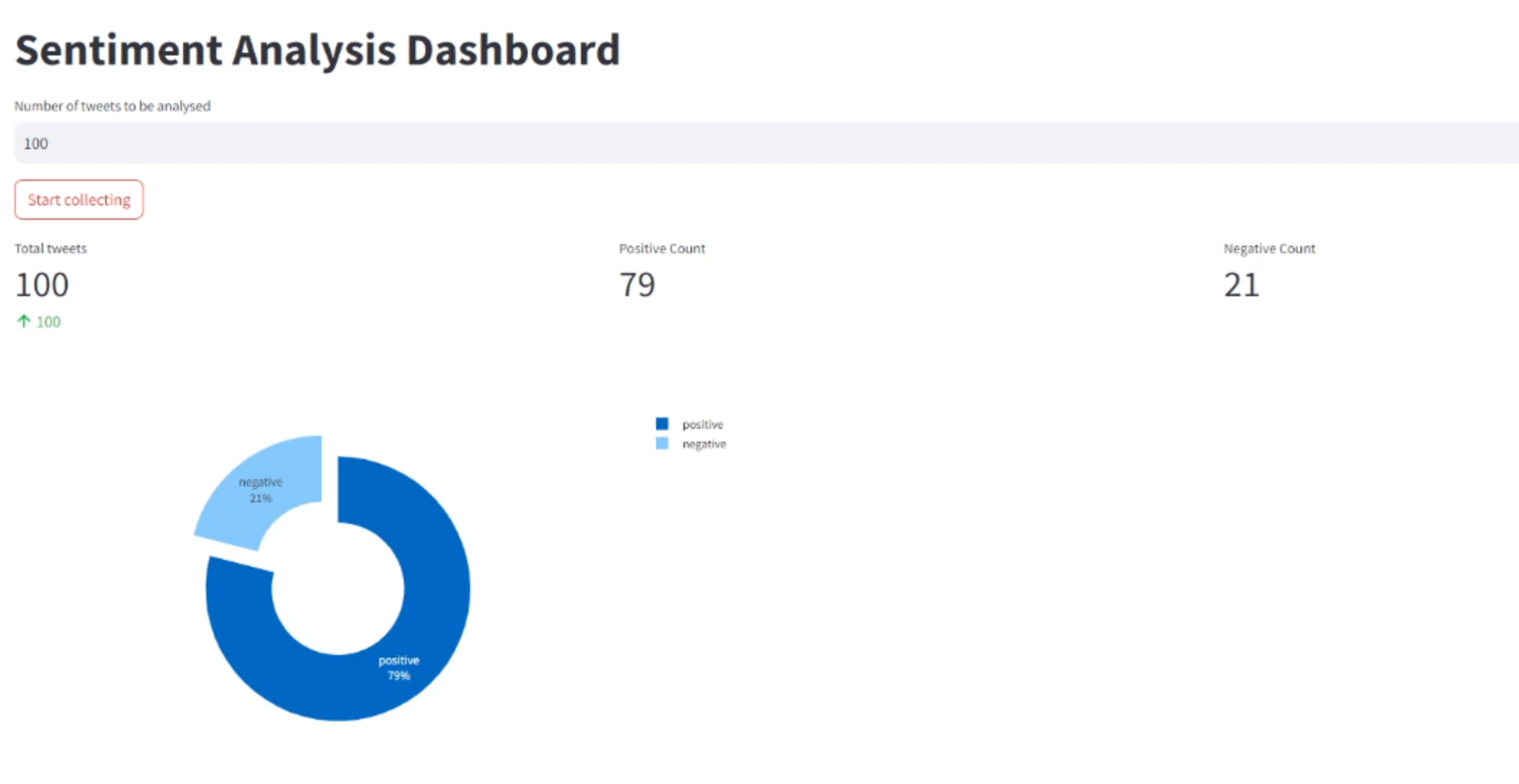
A fully GKE managed Sentiment analysis application with language model training and inference schemes automated using github actions
Objective :
Company ABC. seeks to develop a real-time Twitter sentiment analysis system with a strong emphasis on scalability, high availability, and continuous machine learning model improvement. This system will process Twitter data in real-time, ensuring uninterrupted production even under high loads. Key objectives include the deployment of updated models without downtime, efficient data handling, monitoring, maintainability. The system will also offer a user-friendly interface.
Solution :
The solution was leveraged on modern tools and technologies to build a robust real-time Twitter sentiment analysis system. We utilize GitHub Actions for streamlined code integration and deployment, harness the power of a Kubernetes cluster deployed on Google Kubernetes Engine for scalability, and employ Python as the primary coding language. The heart of our system is a fine-tuned BERT language model, renowned for its accuracy in classifying tweets into positive and negative sentiments. This combination of cutting-edge tools and a powerful machine learning model ensures seamless scalability, high availability, and continuous model improvement. Our solution not only meets the demands of real-time Twitter data processing but also provides valuable insights to users.
Results :
F1-Score of ~81% achieved on testing dataset, which is equivalent to ~ 240 times a document category is correctly predicted out of 300 documents (Test data).
Date:
November 2023
Category:
NLP, classification, labelled dataset, kuberneters, docker, google cloud platform, google kubernetes engine
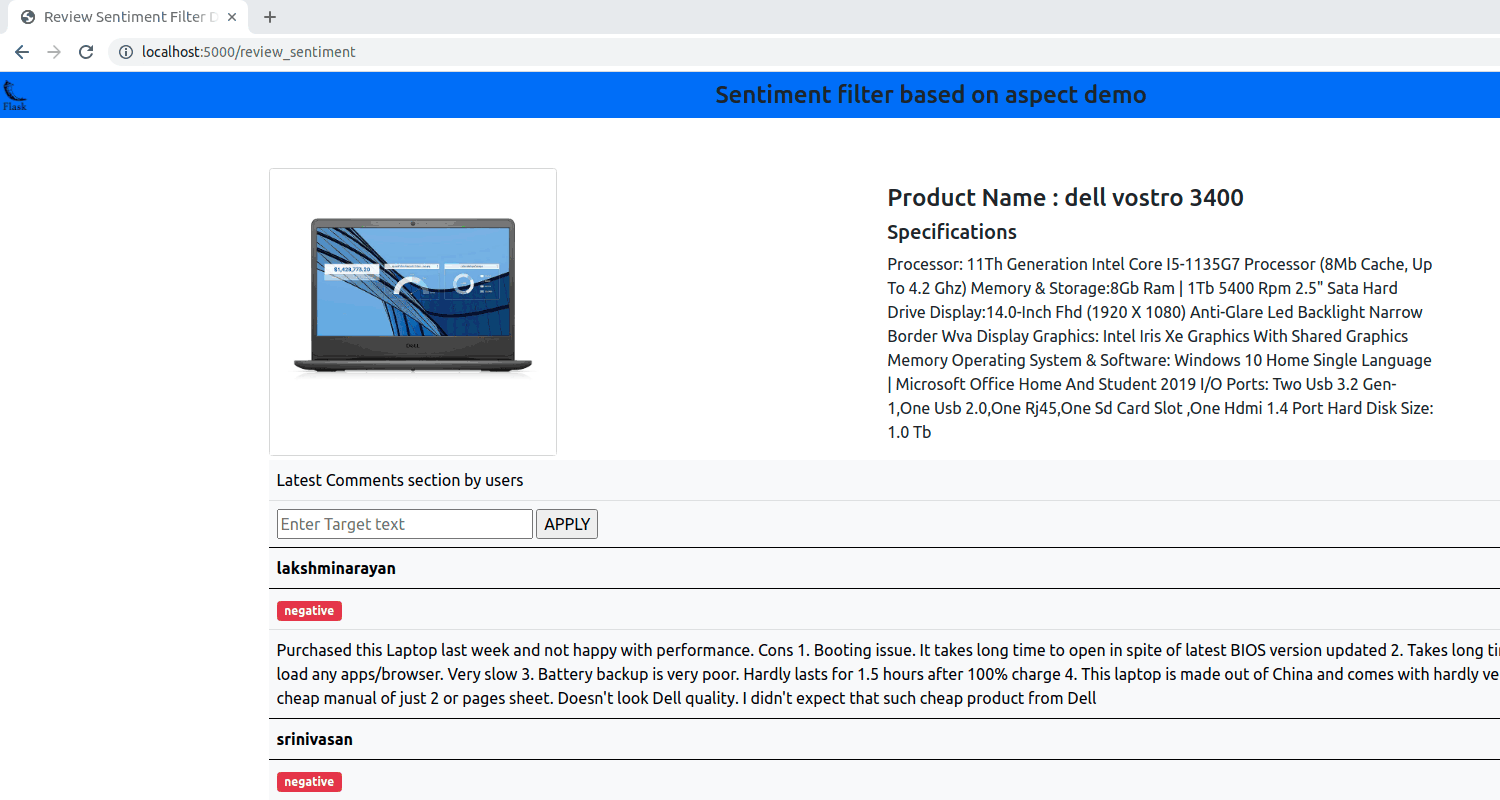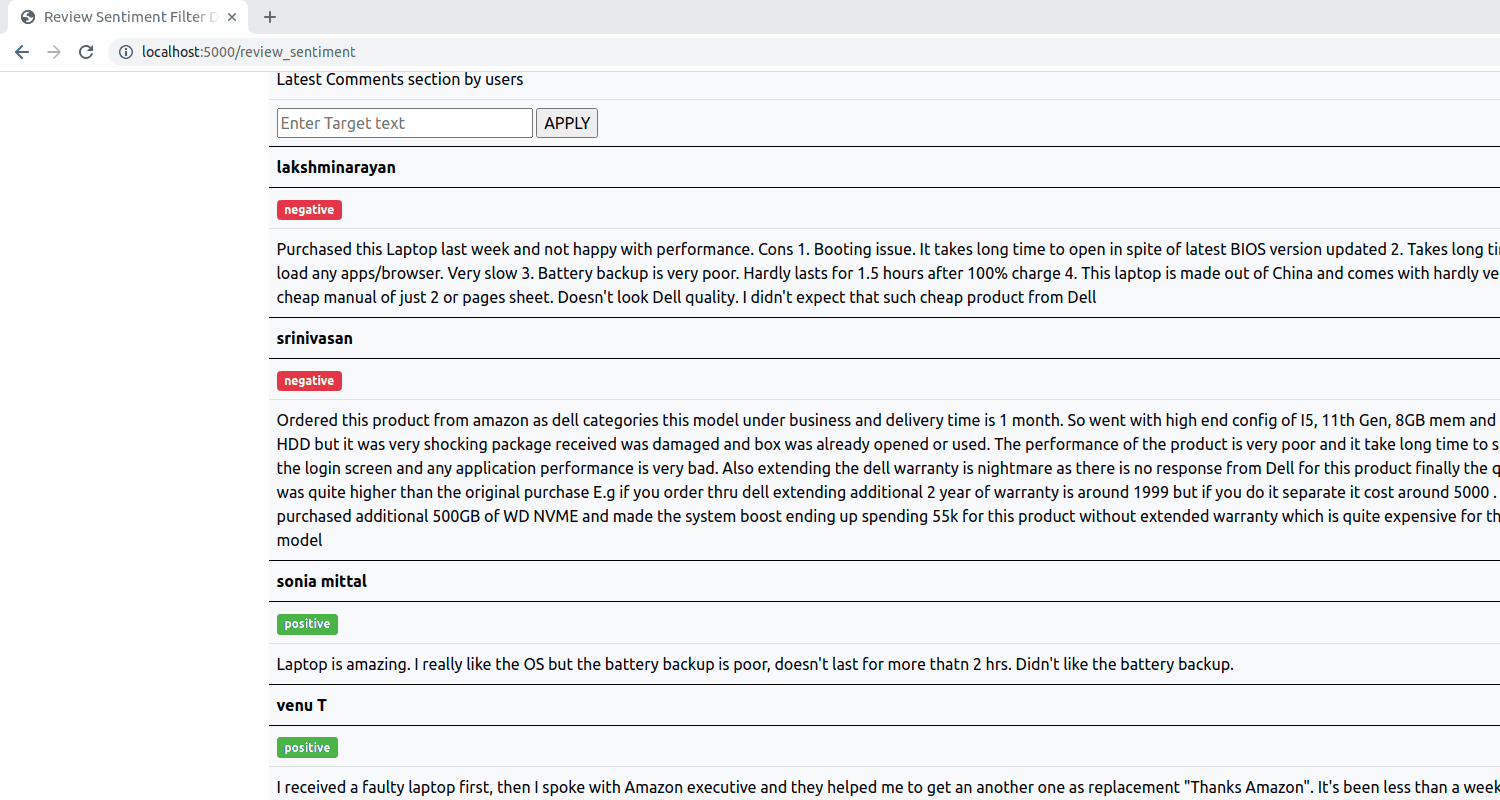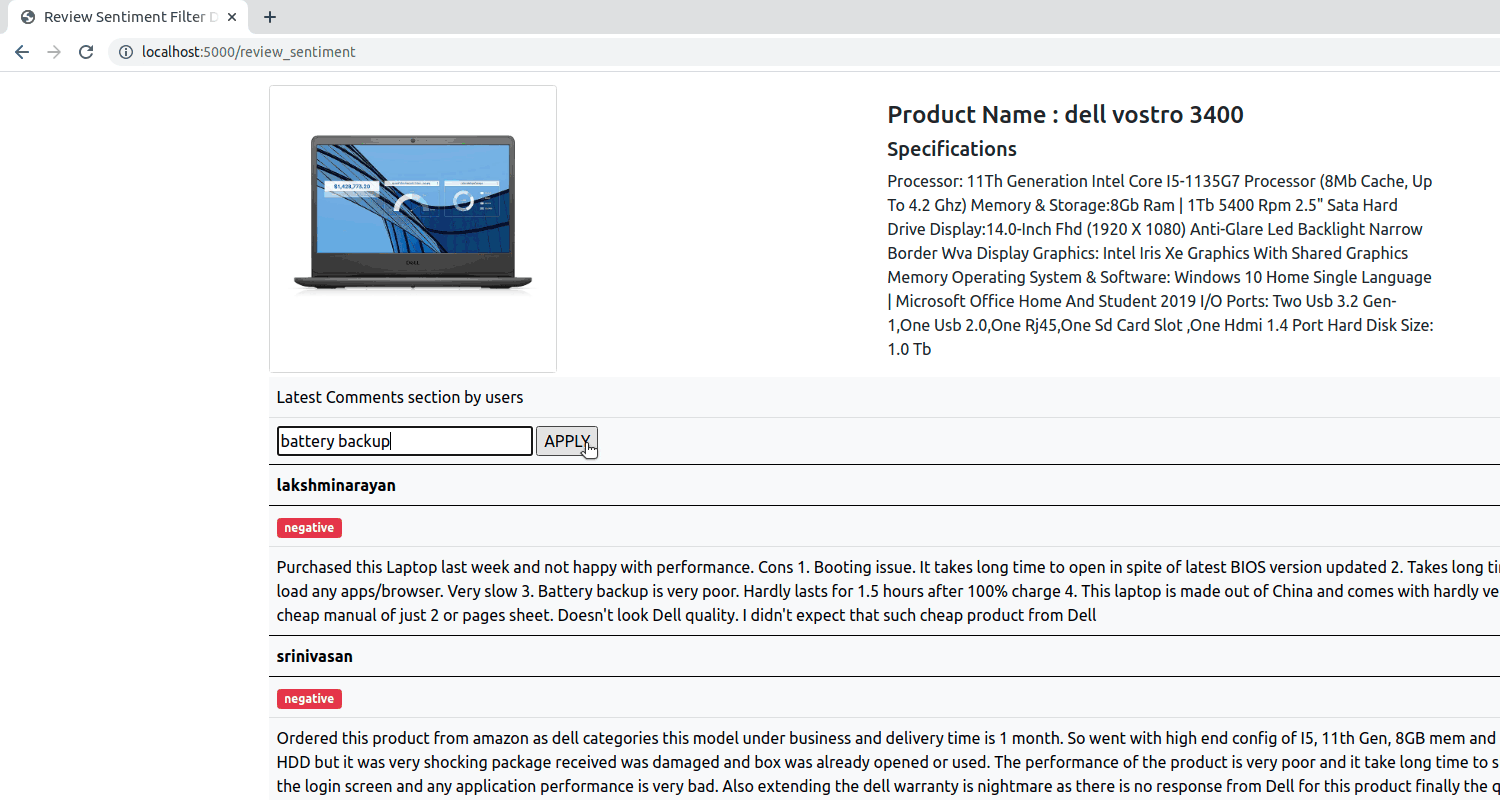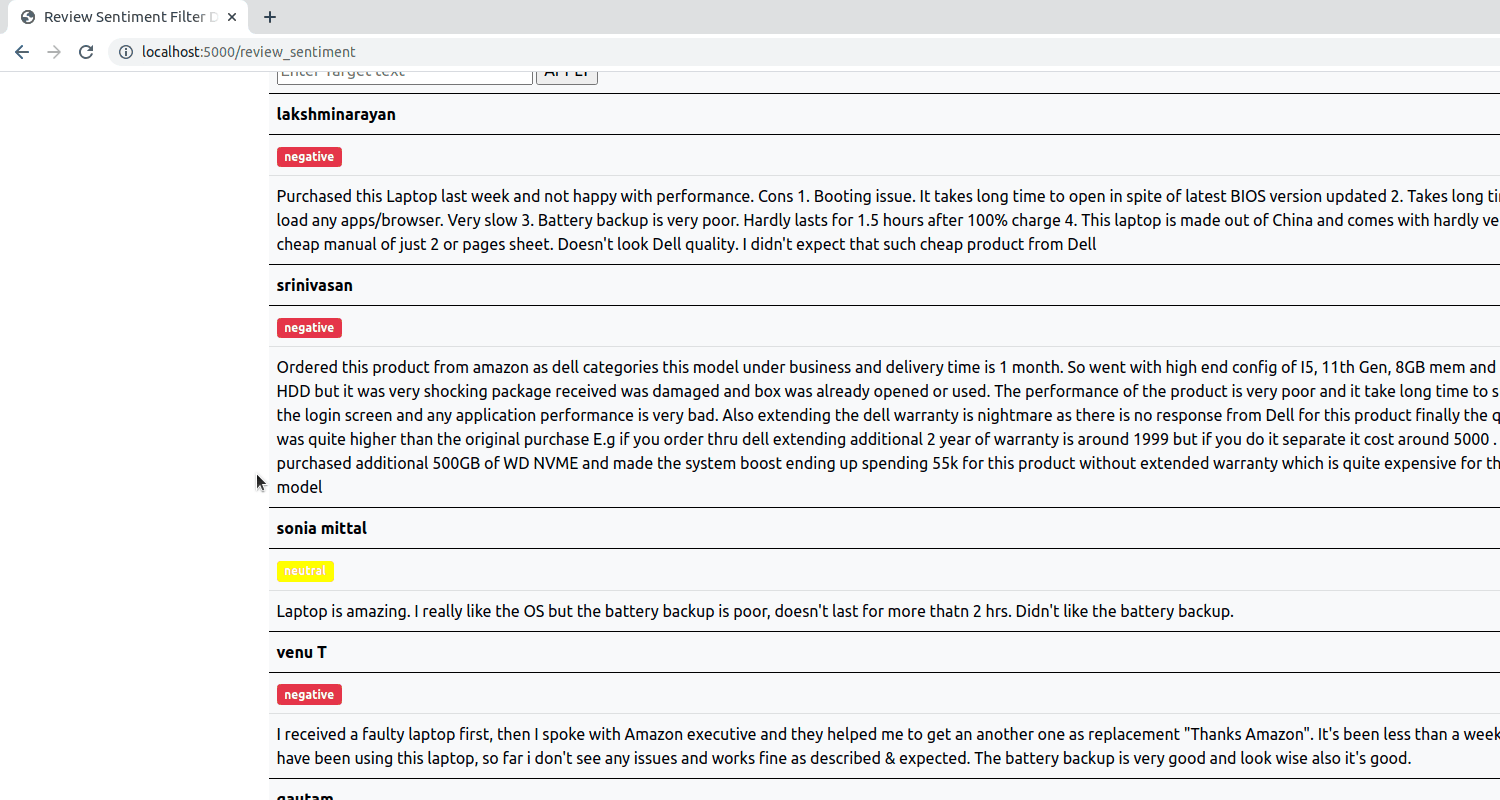
Build an aspect based sentiment analysis model which will be able to predict the sentiment of a review comment from pre defined categories positive, negative and neutral.
Solution :
LSTM neural network is trained with the input word vectors and target(aspect) text. The word embedding is created from the pretrained GloVe Twitter Dataset with 25/125/200 dimension size.
Results :
The training, testing accuracy comparison with a regular LSTM and Aspect based LSTM suggest that the Aspect based LSTM outperforms a regular LSTM and hend concludes the fact that on providing target text to the input the model performs better.
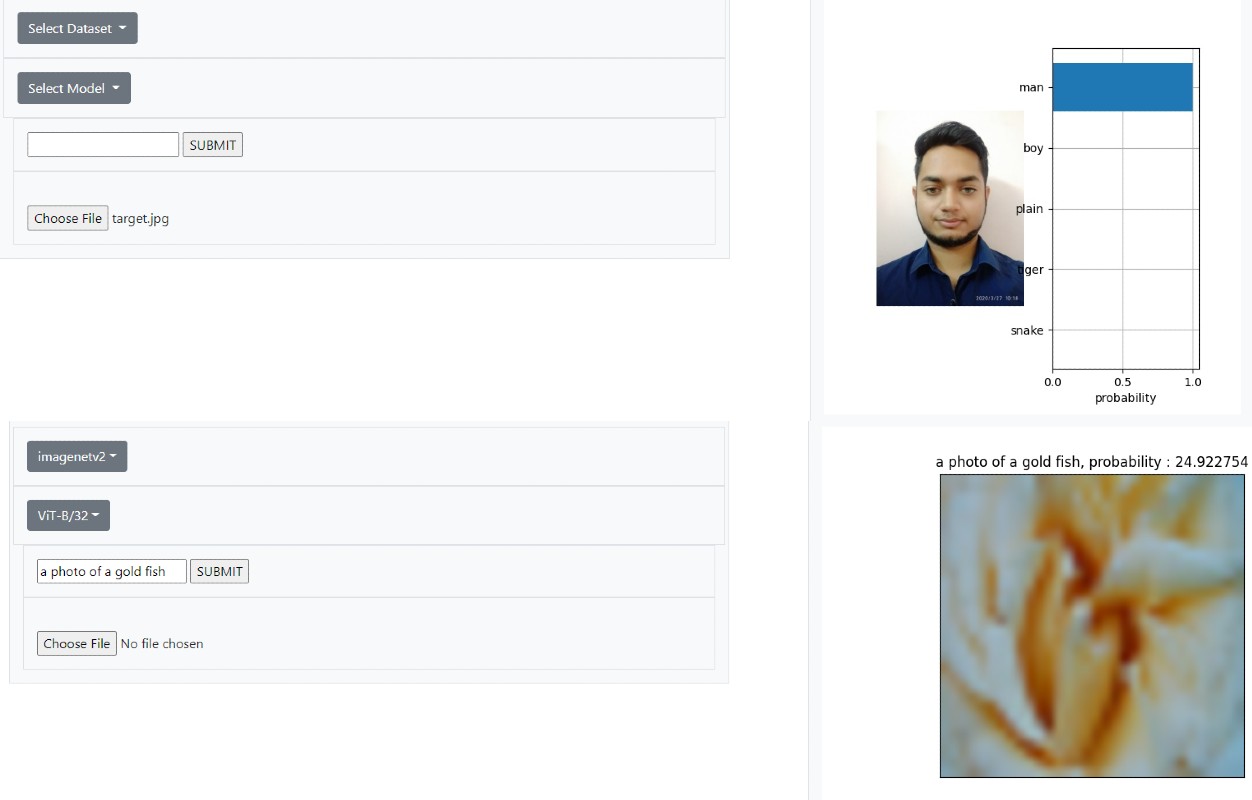
Predict accurate text snippets describing the input image , Generate appropriate image when given a text snippet associated to that image.
Solution :
The solution to this obective starts with a pretraining step which is also called as contrastive learnining step in which the model is trained on the Image representation (created by a transformer as an encoder) and Text representation (created by another encoder) from scratch, the objective of this training is to maximize the cosine similarity between the N real/correct pairs of image representation and the text representation and minimizing the N^2 - N incorrect set of pairs, optimized using a cross entropy. This training creates a multimodal embedded representation which is further used for zero shot classification.
Results :
As mentioned in the research paper it was found that the model matches the performance of ResNet50 on ImageNet dataset without using any of the labeled example in the dataset which overcomes many challenged in computer vision
Date:
June 2021
Category:
NLP, zero shot classifier, image captioning, text to image
Newsgroup classification (with labeled data) inference pipeline with AWS Sagemaker
Objective :
Train a machine learning model with a newsgroup dataset which should be able to categorize a news summary from 20 different news categories. Create an inference pipeline in AWS Sagemaker and deploy it on sklearn docker container.
Solution :
Td-idf is chosen as the word to vector model, MultiNomial Naive Bayes algorithm is used the learning algorithm to learn the category of the document content passed as input to the model. Inference pipeline is setup in AWS sage maker studio, 2 endpoints created (1 for inferencing, and another for training the model on demand).
Results :
F1-Score of ~81% achieved on testing dataset, which is equivalent to ~ 240 times a document category is correctly predicted out of 300 documents (Test data).
Train an image classifier to recognize different species of flowers, with input image of size 224 x 224 .
Solution :
A neural network is created using a pretrained vgg16 model with its fully connected layer replaced with another set of fully connected layer with 102 outputs as we have to predict out of 102 different species of flowers.
Results :
The training results were achieved with the help of google colab GPU which took around 10 minutes to complete for processing a set of 1500 number of 224 x 224 sized images achieving an accuracy of 83 % while training and a testing accuracy of 86 %. This results were improved after considering data augmentation (rotating and resizing) the images during the preprocessing step.
Date:
July 2019
Category:
CNN, Deep Learning, vgg16, Data augmentation, Image recognition
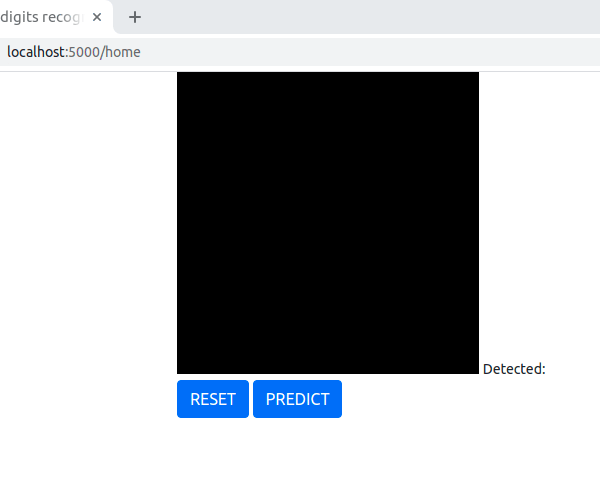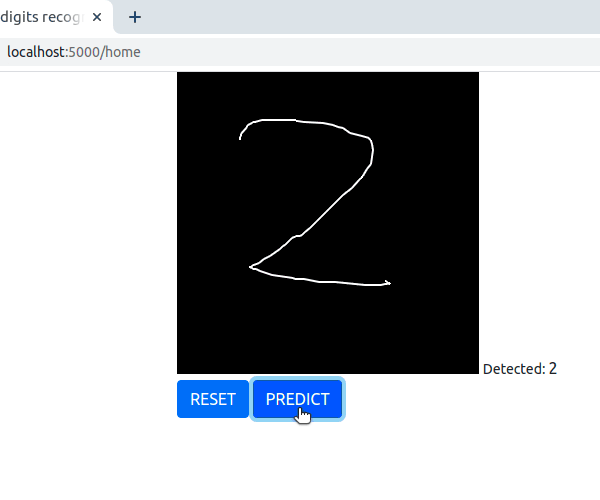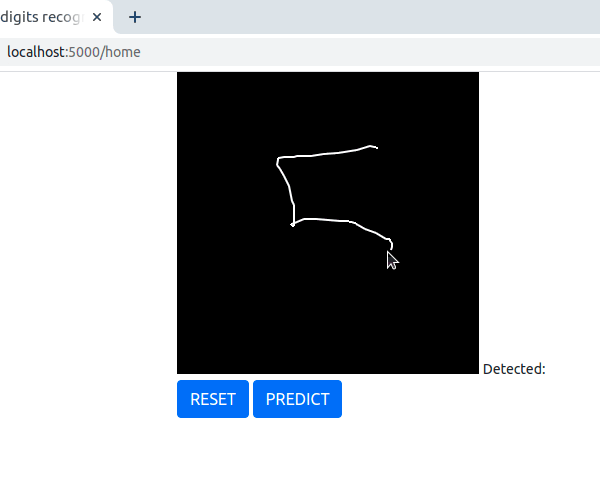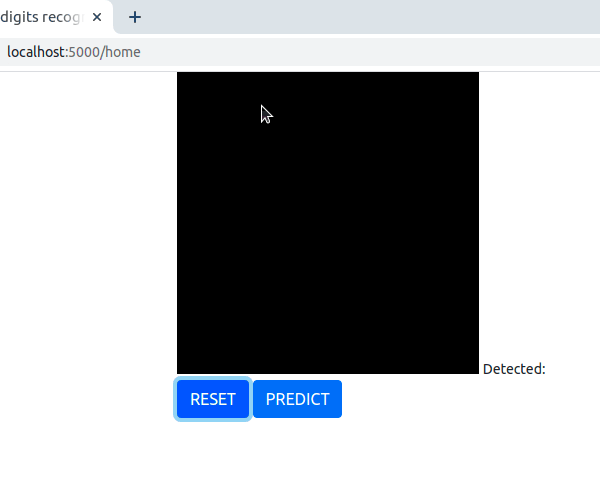
A simple solution for replacing traditional captcha with a handwritten digit recognition using deep learning model.
Solution :
MNIST dataset is used to train a simple CNN based model, the model is then saved and further exposed as a REST api using Flask. With javascript code input image is obtained and processed.
Results :
Test accuracy of 90% was obtained on MNIST dataset, 28x28 sized images were used with the CNN based model.
Date:
July 2019
Category:
CNN, Deep Learning, MNIST, Data augmentation, Image recognition, HTML, JS, CSS
Speech2Text UI and Fine Tuning Wav2Vec2 for English Auto Speech Recognition
Objective :
Generate a transcription of a voice recording which is stored in a sound file
Solution :
A pretrained model - wav2vec 2.0 is loaded which was trained on 50 hours of unlabeled speech recordings from different authors along with different background noises, in this project I have explored two approaches, one involve finetuning of pretrained model and another without any finetuning.
Results :
Word Error rate is used as the metric to measure the performance of the model on testing dataset, which is found to be as low as 8.3 %